The Recording
The Panelists
- Kevin Feasel
- Tracy Boggiano
- Mala Mahadevan
- Tom Norman
Notes: Questions and Topics
A Call for Kerberos Help
Tom kicked us off with a request for assistance around Kerberos, where he was getting an error message I hadn’t seen before:
Cannot connect to WMI provider. You do not have permission or the server is unreachable. Note that you can only manage SQL Server 2005 and later servers with SQL Server Configuration Manager.
Invalid namespace [0x8004100e]
He noticed this Microsoft Support page which explains how to fix it, but that didn’t seem to do the trick. He promises to vanquish this beast and report on it for the rest of us.
Imbalanced Classes and Confusion Matrices
Deepak reached out to me with a question. “I have a labeled data set of about 100,000 employees. I need to predict who will leave or stay with the company. This is highly imbalanced data because most of the employees stay with the company and very few leave. Thus wondering how to prepare the data for training the model? Should I first filter out the data of employees who left the company and then may be use 1000 employees who left the company and may be 200 employees who stayed with the company to train the model? If not, then which AI ML model should I use which can handle highly imbalanced data for classification?”
Answer: This is known as an imbalanced class problem. In this simple scenario, we have two possible classes: left the company (1000) and stayed with the company (99,000). This type of issue explains why accuracy is not the end-all, be-all measure for gauging prediction quality, as I can create a model which is correct 99% of the time by simply saying that everybody will stay with the company.
From there, @thedukeny nudged me into talking about a concept known as the confusion matrix. This leads to four measures in addition to accuracy:
- Positive predictive value: given that we said you would stay, how likely were you to stay?
- Negative predictive value: given that we said you would go, how likely were you to go?
- Sensitivity / Recall: when you actually stay, how often did we predict you would stay?
- Specificity: when you actually go, how often did we predict that you would go?
In cases where the classes are pretty well balanced, accuracy (based on the prediction we made, were we correct?) is not a terrible measure, but we want to temper it with these four additional measures to get a more complete look at how we are doing.
Getting back to Deepak’s direct question, I have one technique and two algorithms which I think work well in these cases. The technique is to oversample (or undersample). When we oversample, we make copies of the lesser-used class in order to balance things out a bit more. Instead of having a 99:1 ratio of stay to go, we might make dozens of copies of the people who go, just to tell the algorithm that it’s not okay simply to avoid that 1% and take the easy 99% victory. The opposite side is undersampling, where we throw away enough of the majority class to get closer to a 1:1 balance. As a note, it doesn’t need to be perfectly even—even a 2:1 or 3:1 ratio is still fine depending on your algorithm and amount of data.
As far as algorithms go, gradient boosted decision tree algorithms (like xgboost) do a really good job of handling class imbalance. Also, one of my favorite sets of classification algorithms does a great job with this problem: online passive-aggressive algorithms. The way this algorithm works is that, for each record, we determine whether the model we’ve created would have predicted the answer correctly. If so, the model makes no changes to its weights—in other words, it is passive. But if the predicted class is incorrect, the model will move heaven and earth to get things right—it is aggressive in changing weights until the current example is just within the boundary of being correct. It then moves on to the next set of inputs and forgets about the changes it needed to make to get the prior answer correct. In this way, passive-aggressive algorithms focus in on the problem at hand and ignore how we got to where we are, and so it treats each input as vital. That’s why we may not necessarily need many examples of a class to get it right as a whole: the algorithm is aggressive enough with every single record that it doesn’t need iteration after iteration of a class to recognize that it’s important to learn something about it.
Presentations and Sessions
@johnfan14 asks, “OK.. You guys attend so many seminars, so how do you manage them? like planning and scheduling.. You use Excel or some kind of calendar or some other tools?”
Answer: Tom, Tracy, and I all gave about the same answer: calendar entries and spreadsheets. I use Google Sheets so that I can access it easily from the road and keep track of when, where, what, and key stats I need for reporting. Here’s a quick sample from 2019:
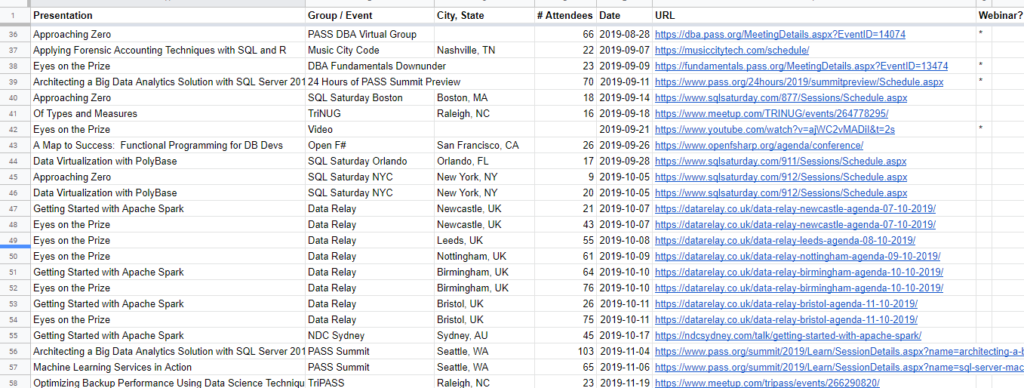
We also use calendar entries to keep track of when and where, and I also have a spreadsheet with travel plans to ensure that I have airplane, hotel room, and rental car (if necessary) booked. Early on in my speaking career, I accidentally double-booked a flight because I didn’t realize I had already purchased a ticket. That’s when I started keeping the spreadsheet.
Database Comparison Tools
From @jeffalope: “Anyone have any cool ways to compare multiple databases where the expectation is that the schema should be the same but you know there is some drift? I know that sqlpackage (ssdt) and red-gate sql compare exist but just wonder if anyone has knowledge of a turn key solution to generate a “report” for a few dozen instances?”
Answer: Tom gave us a website which has a list of comparison tools, but there are two parts to Jeff’s problem. First is a product which generates a comparison between a source database and a target database. Tom’s link gives us a myriad tools for that job.
But second, the requirement to compare a few dozen instances stresses things a bit. I had put together something in the past for Red Gate schema comparisons but it turned into a bit of a mess because of two reasons: first, schema drift happens a bit too regularly; and second, because minor server configuration differences can lead to lots and lots of what are effectively false positive results around things like collation. As a result, I don’t have a great solution but I can confirm that Red Gate’s tool is something you can call from .NET code (I used C# but you could also use F# or Powershell) and build an internal product around.
Mala’s Book Corner
Mala recommended two books for us this week:
Check out both of those books.
Database Design in an Ever-Changing World
We had two similar questions from Data Architecture Day that I’m getting around to answering. First, from @lisanke:
How does the process of DB design change if we tell you, you’ll be working with a group (or groups) of programmers who’ll want to store and retrieve data efficiently from the DB for their tasks (e.g. system test) But they don’t know (yet) what they’ll be storing And that target will always be changing through the development life cycle?? can I create database schema and structure and access procedures that helps the team and won’t be completely inefficient with constantly evolving data design?
And second from @thedukeny: “Tips for balancing normality with development speed?”
Answer: I consider these to be very similar questions with similar answers, so I’ll take them together.
The key question is, do you prototype? I love this story from Phil Factor about Entity-Attribute-Value (EAV) and prototyping. As Phil points out, EAV can work in the early development phase, but as we get closer to a stable product, it needs to be turned into a survivable data model. If you need to get something put together immediately to show off, it’s a workable approach. But the problem I see is that very few companies create proper prototypes, where you have one approach to the problem and then throw it away and start over. That’s a shame, but it is something we have to live with—unless you’re in a lucky situation in which you can create real prototypes and then not immediately ship that code to production.
The other problem we have to live with is that “We’ll fix it in round 2” is a comforting lie we tell ourselves as we write halfway-working code. Round 2 almost never happens because we have so much more stuff to do and by the time we actually have a chance to get back to that code, it’s now “too difficult” to fix.
We also have to keep in mind that databases are stateful and require planning. I can gut a web application and, as long as I haven’t messed with the interfaces, nobody needs to be the wiser. How we get to the current state in a web app is almost unimportant; for a database, it’s the entire story. And this is just as true for non-relational databases as it is for relational!
There are some non-relational databases which might be easier to develop against, so it might make sense to create a prototype in one system and then migrate it to the real system once you’re ready for real development. If you’re in a shop where you can do that, go for it. But there are some risks of performance problems, translation issues, and missing functionality as you make that shift, so build in time for all of that.
I think a better approach is to skip the database while the data model is fluid. If you’re changing your data model on a daily basis, it’s a sign that your product isn’t mature enough for a database. That’s not a bad thing, but save yourself the pain and just use in-memory objects which you can load up from JSON, XML, flat files, or even hard-coded in unit tests if that’s what you really want to do. That way, you can quickly modify the data structure you need in your app as requirements change, and once the model is more stable, then it’s time to negotiate the differences between an application and a properly-normalized relational database.
I think that’s reasonable advice early in the development cycle, which is where @lisanke focused. But getting to @thedukeny’s question, how about when the app is mostly stable but you’re doing regular development?
In that case, we want to have a data model planned out. This data model is different from the application’s objects (or record types or whatever), as your data model typically survives the application. I know of databases which have survived three or four versions of an application, and that’s why it’s important to understand the data rules and data model.
Like all other development, expect changes and re-work based on how well the product has been maintained over time. If you have a model which is generally pretty good, you’ll want to keep it in shape but won’t have to spend too much time rearchitecting everything. If it’s a junk design, build that time in when coming up with estimates for doing work. As much as you can, take the time to get it right and work with the dev team. Most developers want to get things right but don’t necessarily know the best way to do it, so they do what they know and move on. I understand that, like any other group, there are developers of varying levels of work ethic and professionalism, but find the people willing and able to help and work with them.
One last piece of advice which bridges both of these questions is, use stored procedures as an interface. @jeffalope also mentioned this in the context of a data access layer (DAL). Try to keep your database as removed from the business objects as you can, and stored procedures do a great job of that. This way, you can redesign tables with potentially zero impact on the application, as the interface to the stored procedures did not change. It also allows application objects to exist separate from the data model. It’s extra work, but well worth it in the end.